컴퓨터 비전 공부하기(딥러닝 시작하기 - Optimizer)
오늘은 공부하기로 한 손실함수와 역전파를 어떻게 사용하여 학습을 진행하는지 알아보는 시간을 가져보자. 다음은 이 부분을 공부하는데 큰 도움이 된 레퍼런스들이다분을 공부하는데 큰 도움이 된 레퍼런스들이다. 더 많은 그림을 보며 자세히 알고싶다면 참고하도록 하자
이번에는 수식이 많이 나오기 때문에 가독성을 위해서 ChatGPT를 이용하여 수식을 작성하고 분석하였다
https://89douner.tistory.com/46
12. Optimizer (결국 딥러닝은 최적화문제를 푸는거에요)
안녕하세요~ 지금까지는 DNN의 일반화성능에 초점을 맞추고 설명했어요. Batch normalization하는 것도 overfitting을 막기 위해서이고, Cross validation, L1,L2 regularization 하는 이유도 모두 overfitting의 문제를
89douner.tistory.com
오늘 알아보기
1. Momentum
2. Adaptive 방식의 옵티마이저
3. 역전파
4. Step Decay란?
Momentum
Momentum 은 그래프를 탐색하는데 있어서 관성을 준 방법이다.

이 그림을 보면 이해하기 쉽다.
빨간색과 파란색 그래프를 보자. 이 두 그래프 모두 Momentum 개념을 사용한다.
만약 파란색 그래프를 예로 들면, 이전 값에서 얻어진 거리 변화를 이용해 아래로 조금 더 내려가 보거나 조금 더 적게 내려가며 학습을 진행한다. 즉, 이전 기울기의 영향을 받아 마치 공이 굴러가듯 부드럽게 학습 방향이 결정된다.
Momentum의 수식은 아래와 같다.
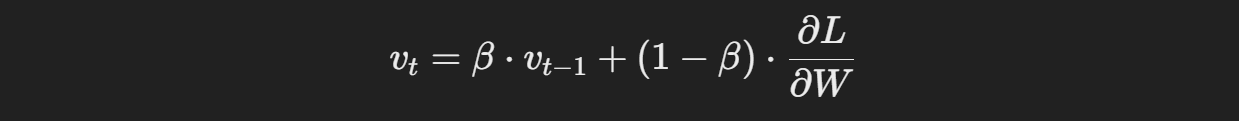
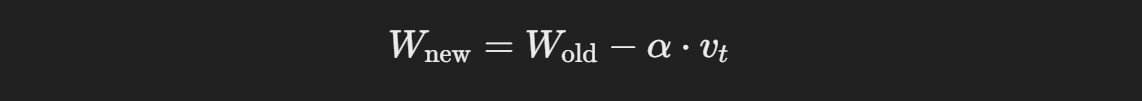
- v_t: 현재 속도
- β: Momentum 계수(일반적으로 0.9)
- ∂L/∂W: 가중치에 대한 손실 함수의 기울기
- α: 학습률
이 수식은 경사하강법에 가속도를 부여해주는 방식으로 작동한다.
TMI // Momentum의 추가 활용
1. 빠른 수렴: Momentum은 평탄한 지역이나 작은 오목한 구역에서 학습이 느려지는 문제를 해결한다.
2. 진동 억제: 경사가 급격히 변하는 영역에서 진동을 줄여 안정적으로 수렴한다.
3. 하이퍼파라미터 튜닝: β 값을 조정해 관성을 높이거나 낮추어 학습 속도를 세부적으로 조정할 수 있다.
Adaptive 방식의 옵티마이저
Adaptive 방식의 옵티마이저는 학습률을 동적으로 조정하며, 중요한 특징에 더 집중한다.
이 방식은 우리가 공부할때 시험에 나오는 중요한 개념을 위주로 공부하고 TMI는 넘기듯이 학습하는 것이 특징이다
이 방식의 종류로는 다음과 같은 것들이 있다
AdaGrad (Adaptive Gradient Algorithm)
RMSProp (Root Mean Square Propagation)
Adam (Adaptive Moment Estimation)
1. AdaGrad
AdaGrad는 각 파라미터에 대해 개별적으로 학습률을 조정한다. 손실 함수에서 기울기가 큰 파라미터는 학습률이 점점 작아지며, 드문 특성을 가진 데이터는 더 많이 학습한다.
AdaGrad의 업데이트 수식은 아래와 같다.
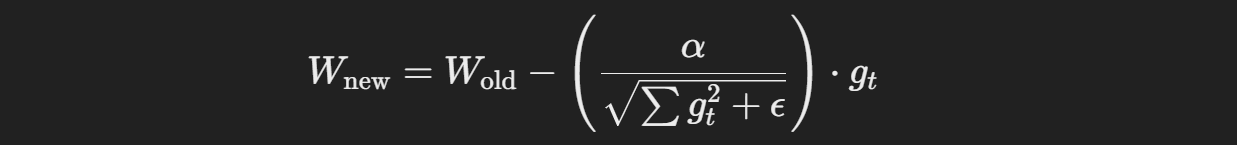
: 업데이트된 가중치
- WoldW_{\text{old}}: 이전 가중치
- α\alpha: 학습률 (learning rate)
- gtg_t: 현재 단계 tt에서의 기울기 (gradient)
: 이전까지의 기울기 제곱들의 합 (즉, 과거 기울기의 누적 값)
- ϵ: 매우 작은 값 (일반적으로 10^{-8}정도로 설정되어, 분모가 0으로 나누어지는 것을 방지)
: 기울기의 크기를 제어하는 부분, 기울기가 커질수록 학습률이 작아지고, 작을수록 학습률이 커짐
TMI - AdaGrad의 실제 활용
1. 희소 데이터에 유리: 자연어 처리에서 단어 임베딩처럼 드문 데이터에 대해 효과적이다.
2. 과거 기울기의 제곱합: Σ g_t^2 값이 계속 누적되므로 학습 후반부에 학습률이 거의 0에 가까워질 수 있다.
2. RMSProp
RMSProp은 AdaGrad의 문제를 해결한 방식이다. 과거의 모든 기울기를 고려하지 않고, 최근의 기울기 정보만 사용한다.
수식은 다음과 같다.
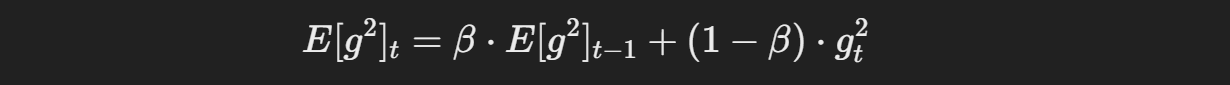
: 현재 시점 t에서의 기울기 제곱의 지수 이동 평균
- β: 이동 평균을 계산할 때 사용되는 지수적 감쇠 계수 (보통 0.9)
- gt^2: 현재 시점 t에서의 기울기 제곱
- E[g2]t: 이전 시점에서의 기울기 제곱의 지수 이동 평균

: 업데이트된 가중치
- WoldW_{\text{old}}: 이전 가중치
- α: 학습률 (learning rate)
- gt: 현재 시점 t에서의 기울기
RMSProp은 특히 순환신경망(RNN) 모델에서 좋은 성능을 보인다.
TMI: RMSProp의 강점
1. 진동 억제: RMSProp은 진동을 줄이면서 안정적으로 학습할 수 있다.
2. 지수 이동 평균: 최근 데이터에 가중치를 더 주어, 최신 기울기에 민감하게 반응한다.
3. Adam
Adam은 AdaGrad와 RMSProp의 장점을 결합한 방식으로, 학습률을 각 파라미터마다 다르게 조정하며, 모멘텀 개념까지 도입한다.
Adam의 업데이트 수식은 다음과 같다.
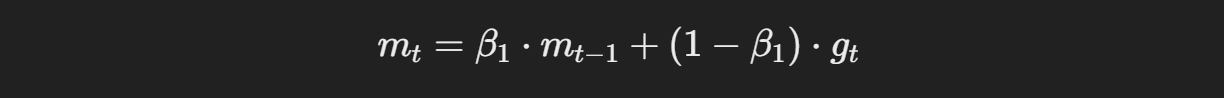
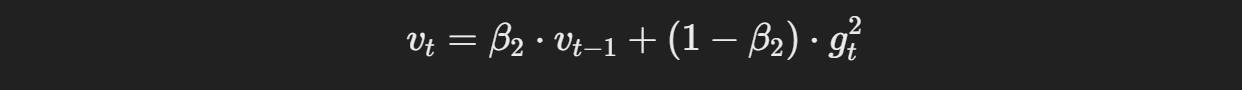


모멘텀은 기울기의 평균을 이용하여 빠르게 수렴하게 돕고, 스케일링을 통해 기울기의 크기 차이에 따라 학습률을 자동으로 조정한다
이후 편향 보정을 통해 초기의 기울기 추정치가 0에 가까운 편향을 보정하여 최종적으로 가중치를 모멘텀과 스케일링된 기울기를 바탕으로 업데이트한다
TMI - Adam이 잘 동작하는 이유
1. 조합의 강점: AdaGrad의 개별 학습률 조정과 RMSProp의 안정성을 결합했다.
2. 적은 튜닝 필요: 초기 하이퍼파라미터로도 좋은 성능을 낸다.
3. 넓은 활용: 이미지 처리, 자연어 처리 등 다양한 딥러닝 문제에서 효과적이다.
역전파 (Backpropagation)
역전파는 출력층에서 계산된 오차를 입력층으로 전파해 가중치를 업데이트하는 알고리즘이다.
순전파 (Forward Pass)
입력 데이터를 통해 출력을 계산하며, 각 계층의 출력을 순차적으로 계산해 최종 출력값을 구한다.

오차 계산
출력층에서 계산된 값과 실제 값(레이블) 간의 차이를 손실 함수(Loss Function)를 사용하여 오차를 계산한다
예를 들어 평균 제곱 오차(MSE)는 다음과 같이 계산된다.

역전파 (Backward Pass)
출력층부터 입력층으로 오차를 전파하면서 각 가중치에 대한 기울기를 계산한다
이 과정은 연쇄 법칙을 사용하여 각 가중치의 기울기를 구하는 방식이다
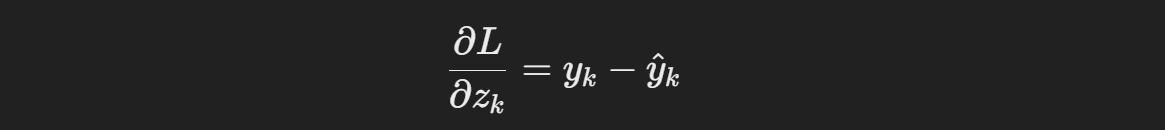
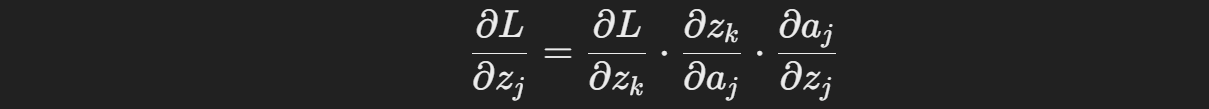
가중치 업데이트
이제 계산된 기울기를 바탕으로 가중치를 경사 하강법등의 최적화 알고리즘을 사용하여 업데이트한다
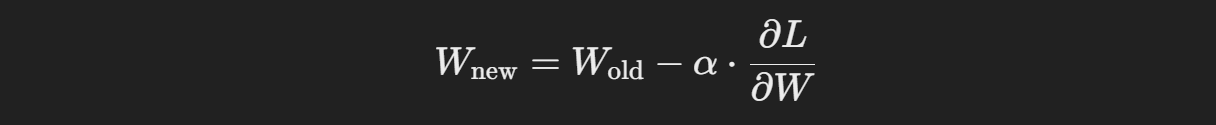
TMI: 역전파의 확장
1. 연쇄 법칙: 복잡한 신경망 구조에서도 손실을 효율적으로 전파할 수 있다.
2. 효율성: CPU와 GPU에서 모두 빠르게 작동하도록 최적화되어 있다.
3. 한계점: 깊은 신경망에서 기울기 소실 문제가 발생할 수 있다. 이를 해결하기 위해 ReLU와 같은 활성화 함수가 사용된다.
Step Decay란?
Step Decay는 학습률을 일정 주기마다 감소시키는 기법이다.
Step Decay의 수식

- η_t: 현재 학습률
- η_0: 초기 학습률
- decay_factor: 학습률 감소 비율
- step_size: 학습률을 조정하는 간격
간단하게 정리해서
t번째 단계에서의 학습률을 일정주기마다 줄여준다.
앞에서 공부한 학습에 가속도를 주는등으로 속도를 조절하는 방법은 학습하는 도중에 불필요한 진동이 많이 발생할수 있다. 하지만 이 방법에서는 처음에 학습률을 크게 잡았다가 점점 줄여서 더 세밀하게 학습률을 조정함으로써 최적값을 더 잘 조정할수 있게 할수 있다
장점
- 효율적인 학습: 초기에 큰 학습률로 빠르게 최적화하고, 학습 후반부에는 작은 학습률로 세밀하게 조정할 수 있다
- 쉬운 구현: 간단한 수식으로 학습률을 조정할 수 있어 직관적이고 쉽게 적용 가능하다(진짜 쉬움)
- 조정 가능: 사용자가 decay_factor와 step_size를 조정하여 학습 속도를 유연하게 관리할 수 있다
단점
- 비연속성: 학습률이 갑작스럽게 변하기 때문에 학습 곡선에서 진동이 발생할 가능성이 있다
- 고정된 스케줄: 미리 정의된 step size를 사용하므로, 데이터나 모델 상태에 따라 동적으로 조정하지 못한다
- Fine-tuning 어려움: 적절한 step_size와 decay_factor를 선택하지 않으면 학습 성능에 부정적인 영향을 줄 수 있다(제일 어려운 부분)
TMI: Step Decay를 잘 사용하는 팁
- fine-tuning: Transfer Learning에서 마지막 단계의 정밀한 학습에 적합하다(어렵지만 적합하다).
- 단계 설정: step_size를 지나치게 작게 설정하면 과도한 학습률 변동이 생길 수 있다.
이 코드도 나중에 시간되면 써먹어보자
from tensorflow.keras.optimizers.schedules import ExponentialDecay
from tensorflow.keras.optimizers import Adam
initial_learning_rate = 0.1
lr_schedule = ExponentialDecay(
initial_learning_rate=initial_learning_rate,
decay_steps=3, # 3 epochs마다 학습률 감소
decay_rate=0.5, # 학습률을 0.5배로 감소
staircase=True
)
optimizer = Adam(learning_rate=lr_schedule)
오늘은 Momentum, Adaptive 방식의 옵티마이저, 역전파, Step Decay에 대해서 알아보았다 이렇게 몇주에 거쳐 딥러닝의 학습 방법에 대해 알아보니 우리가 주로 어떤 방법으로 학습을 진행하며 이를 다양한 방법으로 최적화 시키고 있다는 것도 눈에 들어오게 되는것 같다(학습곡선의 최적화가 우리가 머리를 싸매고 고민해야 하는 것이 아닐까?)
아주 개인적으로 이렇게 여러가지 학습방법을 배워야 할까에 대한 의문이 들었지만 이 생각을 내려놓고 최근에는 어떤 학습방법을 사용하는지 알아보도록 하자. 참고로 Step Decay 도 최근에 사용한다는 학습방법이다.